Help your users when your web app crashes
April 21, 2020

Note: This post came from my work on Surviving Other People's APIs. I've been working on a chapter on Async - the content below came from that writing, but doesn't quite make sense in the context of the book. I didn't want to scrap it entirely, so it's found its way into a blog post. I'd love to know what you think!
Plan for things to go wrong
Setting up an interface to pull data from an API asynchronously is a clear upgrade over the alternative; we're now able to update the content on a given page without reloading all of the markup and assets (images, css, etc) on the page. For better or worse, your asynchronous upgrades will also introduce some potential for things to go wrong for the people using your app. Once again, this is an opportunity to anticipate the things which might go wrong, and build fallbacks for when they do.
Dealing with dropped connectivity
Even if you've used a hyper-modern, robust websocket-enabled API-calling technology, at some point or another, the folks using your app will lose their internet connectivity. This isn't just the canonical example of someone on a train going through a tunnel, either. Often times connectivity will go down briefly for mobile users when they switch from a cellular connection to wifi, or when they go between wifi networks, or when they lose wifi and go back to cellular.
You should test your software to make sure it will continue to work in these cases. It turns out this can be pretty easy to simulate, too - if you're on a phone, turn airplane mode on, wait a moment, and then switch it off again. On a laptop or desktop developer environment, you can switch wifi off, or disable your LAN connection. Even better, if you're using Chrome devtools, you can use their responsive tools to shut off connectivity on a single tab:
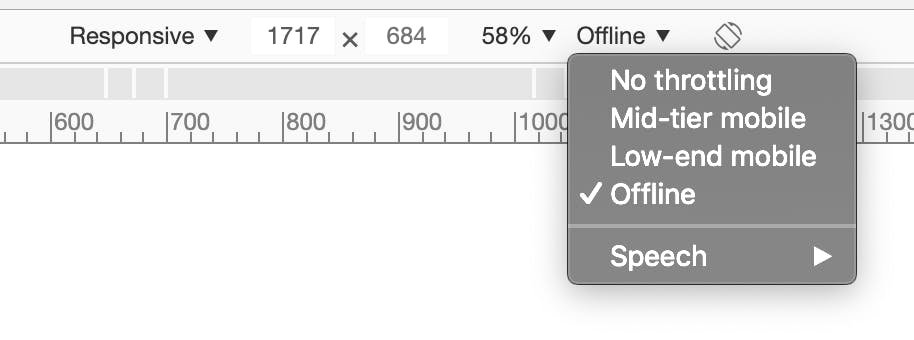
Once you're able to simulate this kind of trouble, you can build out fallbacks for when things go wrong. A typical approach to this is to keep track of the result of your API call locally. If a drop in connectivity is detected, you should let the user know that it looks like they're offline. From there, you can give them the opportunity to retry the API call, and automatically retry your call when you can tell things are working correctly again.
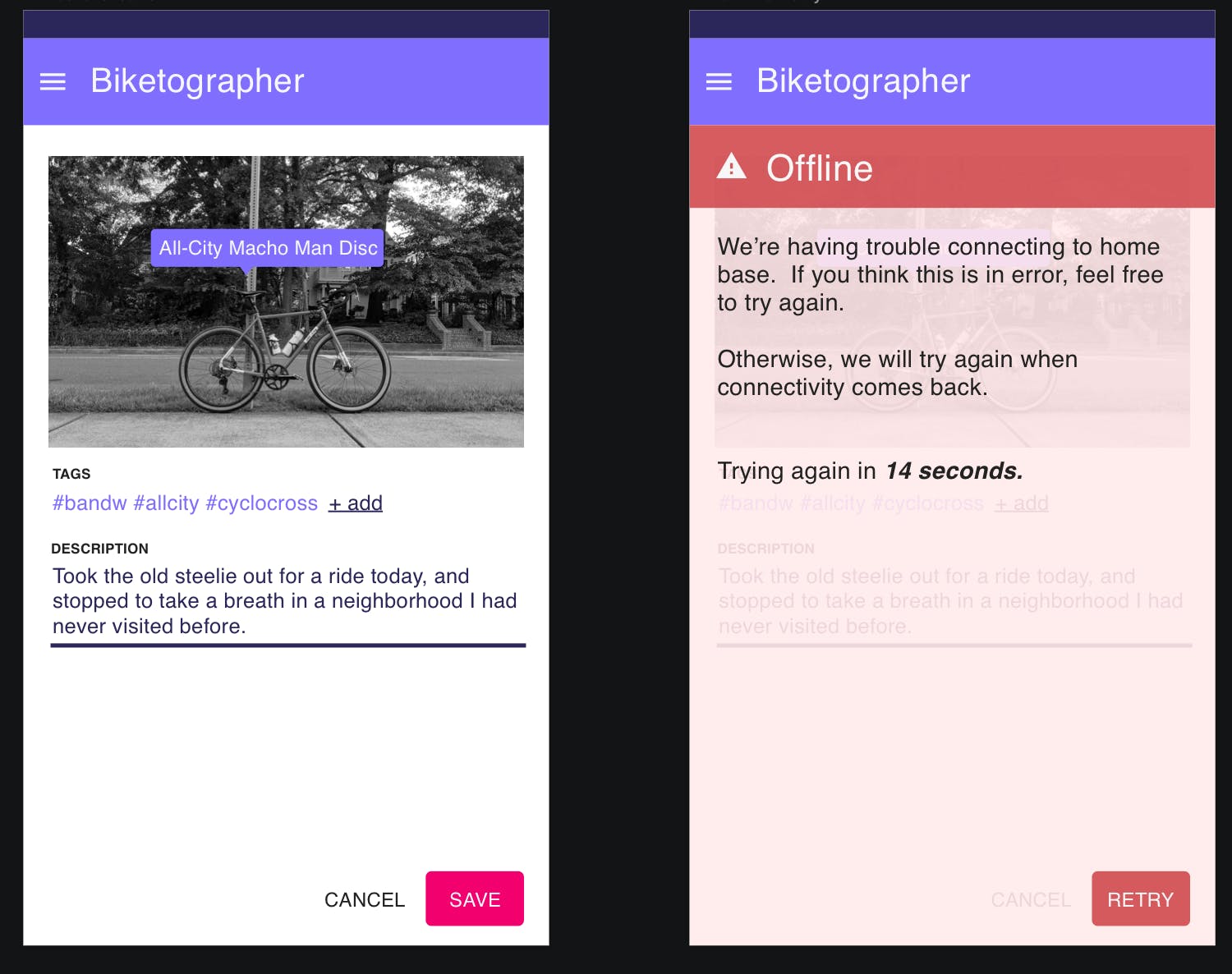
Certain technologies will do the bulk of this work for you. For example, if a connectivity drop is detected, Firebase will save any API operations to a queue in the client browser's local storage, and will execute offline changes as soon as connectivity comes back. Even still, as when creating interfaces which take advantage of features like this, you should let your users know when they're offline. It's best to fully communicate what will happen when the connection comes back, too - in clear, human-friendly language.
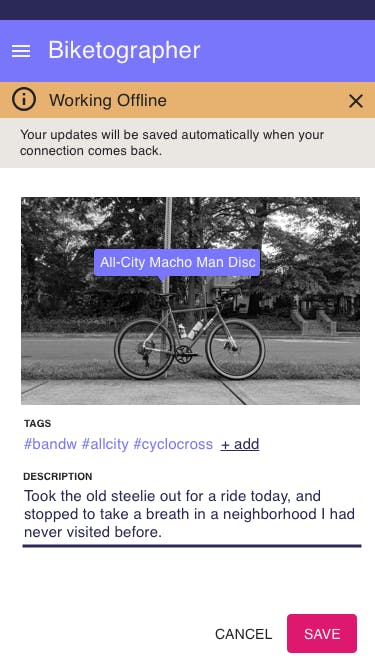
Note that in this case, we have the opportunity to create an interface which is a whole lot less shouty than in the last example. There's no need for the offline notice to be put in a modal window which takes up the whole screen. Colors are dialed back a bit, too - yellow is used in the example, which is much less anxiety-inducing than the-sky-is-falling-red.
As a follow-up to this, when the connection comes back, it's good practice to fire off a notification when the offline requests are completed successfully.
Dealing with changing APIs
At some point, the APIs you're calling will change. In an ideal world, these sorts of changes are well-documented, and deprecation notices are made available months in advance of permanent changes which will break your application. It is part of your team's job to keep an eye on any services you use for breaking changes coming your way. This can be as simple as assigning a task every sprint to check for API and dependency updates.
This is a perfectly functional approach to watching out for version changes -- until it isn't. For larger applications, you may find that as you build more features which depend on a growing number of external services and dependencies, this task becomes an untenable time sink. Luckily, in many cases, there are ways to automate the process. One such tool is called Dependabot, which is owned by the folks at GitHub.
Dependabot (and services like it) will keep an eye on dependency lists in your project (like package.json in Node projects, and Gemfile in Ruby projects). Once initialized, it will regularly check your dependency lists against the published versions of each library. When new versions are published, it'll open a simple pull request for each updated library, which you can review, test, and merge when ready.
Generally speaking, this makes the task of keeping dependencies up to date much simpler. The majority of the work can now be done by your test suites via CI - and changes can be verified by reading changelogs for each updated package.
As this becomes more common, maintainers of various libraries are getting better at posting easy-to-understand changelogs, which reduces the chances that you'll merge a catastrophic change into your project. These kinds of proactive measures should help you sleep more soundly at night.
Even still, sometimes things go wrong for one reason or another.
Maybe you merged and released a dependency update which has a breaking change to a mission critical API. Maybe one of your web page uses an API with a version set to @latest (!), and you wake up one day to find hundreds of help tickets from people who used to love your application. If you had been keeping an eye on server logs for your application, you may have noticed that overnight you received a spike in 4xx or 5xx errors from API calls. Be honest with yourself - how often do you proactively check server logs for errors? Don't fault yourself if the answer is less than often - most of us never check.
Once again, this is a place where automation can save the day. There is no shortage of tooling available to help you detect problems reactively just as they start, and with a nimble enough release strategy, you can minimize application downtime.
Use error reporting to turn reactive situations into proactive messaging
Imagine this: you're in charge of an application which uses an external service to check the weather for [whatever purpose]. You've got thousands of happy users who regularly use your app to check the weather before going about their day. One day, without warning, the weather API begins sending back data in a completely different format than you'd expect - a change big enough to render your app useless.
In the old world, you wouldn't find out about this problem until help tickets and angry tweets started rolling in. At that point, it's past too-late - your beloved customers are upset, and you're the fireman who showed up after the roof collapses on your house.
We can do better than that.
There are a plethora of services available which will detect and report application crashes to you the instant they happen, so your support team can spring into action at a moment's notice. Some of these services include Raygun, Sentry, LogRocket, Rollbar, and Data Dog. With a few lines of code, these will plug into your app, and keep an eye on network requests. When a page crashes, they'll fire off all manner of notifications - SMS, email, webhooks, Slack messages, you name it.
If you can't afford to use one of these services, or otherwise prefer not to, you can scrap together a simple one yourself. This generally looks like a wrapper function which you can use to call APIs. It should contain the logic to detect failures, and fire off whatever calls are necessary to alert your team to the problem. For teams with a small budget, the easiest approach may be using Slack's incoming webhooks feature to send a message to a channel dedicated to an application crash:
const callApi = async ({url, options}) => {try {// send off the API callconst response = fetch(url, options);return response;} catch (e) {//something went wrong, let's notify the team!/* helper function to gather as much information as possible about this session, possibly including:- user name and contact information- URL or page they were visiting- which action caused this error- browser metadata ("IE7" or "Firefox 58", etc)- anything else that might help your support team send a thoughtful, personal response!*/const metadata = getUserMetadata();// just what it sounds like - send a message to your team's slack channel via incoming webhooksendSlackWebhook({error: e,metadata: metadata});// send the response back to the interface so you can let the user know something went wrongreturn e;}}
These can greatly decrease your effective response time. If you're able to detect these problems and set your dev team off on a solution before users start complaining, the people using your app will feel loved. Think about how rare it is to use software and feel like the people who are making it care about you directly! If you're a small, scrappy start-up, this can really help you hang on to early customers. If you're a larger company, it means lower attrition rates, and better support ratings.
Error reporting can also help you detect crashes with user-by-user granularity. You may see crash reports coming in from a single user over and over. Reaching out to that individual to see how you can help them before they message you can honestly feel like magic. I've even had users thank me for dropping them a line and telling them I see that they're having trouble, and that I'm on the case. It's a great feeling - particularly when the alternative is a red-hot support email or a scathing tweet.
Build a global status indicator... before you need it!
In all of the projects I work on, it's become common practice to include a global status indicator into the fundamental roots of the application. In its simplest form, this amounts to a content container that lives somewhere near the very top of every page off the application. The vast majority of the time, it sits invisible and dormant. On page load, and once every few minutes it checks our CMS for content - if something goes wrong, we use that field in our CMS to alert users to the issue, and update it regularly with easily understandable messages about resolution of the issue.
If you don't use a CMS, never fear - you can use something like GitHub Pages to host a json file which you can use for these kinds of warnings. Have your interface check the public URL of your GitHub Pages site, and if there's anything more than a blank file or object, that content can be parsed and displayed in your status indicator.
And then?
For now, that's it! Like I mentioned, this was just an excerpt from a chapter that didn't quite fit with what I'm writing. What do you think? Is there anything you do to harden your site against failures that are out of your control?

